一种融合数据新鲜度的联邦学习动态激励机制

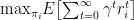
打开文本图片集
关键词:联邦学习;激励机制;多智能体强化学习;数据新鲜度
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2025)08-033-2497-06
doi:10.19734/j.issn.1001-3695.2025.01.0012
Dynamic incentive mechanism for federated learning incorporating data freshness
Dawulie Jinensibieke 1,2,3 ,Wang Yi 1,2,3 , Zhou Xi 1,2,3 ,Wang Xiaobo 1,2,3† (1.XinjiangTclsefi&strecdefec,Uu1Uesitde fSciences,Bino9,ina;.XinjangLbotoryfnoritySpech&LangugeInfomationProcessng,Uruq301,ina)
Abstract:Inmulti-roundfederated learning,thetrainingenvironmentisconstantlychanging.Incentive mechanismsbasedon multi-agentreinforcementlearning(MARL)canbeteradapttodynamicenvironmentsbydynamicallyadjustingdatacontributionstrategies.Existing MARL-basedmechanismsoftenfocusondataquantity,neglectingdatafreshness,whichleadstoicomplete contribution evaluationand limits modelperformance.Thispaper proposed a dynamic incentive mechanismfor federated learning incorporatingdatafreshness.Itintroduceddata freshnessmetricsand benefit evaluationmethods tomorecompreensivelyassesscontributions.Themechanismemployedacentralizedtraining withdecentralizedexecutionMARLframeworkto addresscoordinationissues,maximizingoverallbenefits.Experimentalresultsshowthattheproposedmethodimprovesoveal benefitsby approximately 11.1% to 25.0% across five public datasets.Comparative and ablation experiments further validate the fairness and effectiveness of the method under varying data quality conditions.
KeyWords:federated learning;incentivemechanism;multi-agent reinforcement learning;data freshness
0 引言
联邦学习(federatedlearning,FL)技术允许多个参与方在无须共享原始数据的情况下协同训练模型,有效解决了多方模型训练过程中的隐私和安全问题[1]。(剩余16465字)
