基于情感引导-扩散模型的藏族音乐生成网络

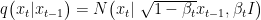
打开文本图片集
关键词:藏族音乐生成;扩散模型;情感引导;tokendrop;self-conditioning中图分类号:TP183 文献标志码:A 文章编号:1001-3695(2025)08-005-2283-07doi:10.19734/j. issn.1001-3695.2025.01.0014
Emotion-driven diffusion model for Tibetan music generation
Song Ziniuab,Peng Chunyanab†,Wang Longhuiab,Zheng Yuhuia,b (a.Collegeofomputerb.StateKeyLaboratoryfetanIntellgence,QinghaNmalUniversityXinngoCina)
Abstract:Artificialintellgencehasachievedremarkableprogressinmusiccreation,yetresearchontheautomaticgenration of Tibetanmusicremainslimited.Currentstudiesface threekeychallenges:inadequate expresionofspecificemotionsefficiencyinhandlinghigh-dimensionalfatures,andinsuficientcontextualconsistencyingeneratedmusic.Toddresseseissues,this paperproposedanemotion-drivendifusionmodel(EDDM)basedontheVAE-difusion framework.This modelutilizedavariationalautoencoder(VAE)toextractessentiallatentfeaturesfromaudiodataand modelsthemduringthedifusion processEDDMintroducedthreecoreinnovations:embeddedanemotionfeatureencoderviacross-attentiontoenableprecise expresion of Tibetan music’sunique emotionsand styles,introduced a token drop strategy to filter redundant features and enhancediversityandrobustness,and proposed aself-conditioning mechanism to ensure contextual coherencebyleveraging prior-step informationfornext-stepgeneration.ExperimentalresultsshowthatEDDMachievesstate-of-the-artperformance, outperforming existing methods in objective metrics such as FAD (2.35↓ ), JSD (0.08↓ ),and NDB (18↑ ),while also exceling insubjectiveevaluationsbyproducingmusicwithstrongemotionalexpresionandfeatureconsistency,showcasingits innovationandvalueinethnic musicgeneration.TheemotionallyguidedTibetanmusic generatedinthis workispubliclyavailableat https://szn1998.github.io/.
Key words:Tibetan music generation;diffusion model; emotion-driven; token drop;self-conditioning
0 引言
近年来,人工智能赋能音乐生成领域取得了显著的进展[1,2]。(剩余18876字)
