一种图文协同层级融合的多模态命名实体识别方法

打开文本图片集
关键词:多模态命名实体识别;语义对齐偏差;语义增强;模态协同;注意力机制中图分类号:TP391.1 文献标志码:A 文章编号:1001-3695(2025)08-019-2390-08doi:10.19734/j. issn.1001-3695.2025.01.0021
Visual-text cooperation and hierarchical fusion for multimodal named entity recognition method
Feng Guangat,Liu Tianxiangb,Yang Yanrub, Zheng Runtingʰ,Zhong Tinga,Lin Jianzhonga,Huang Rongcan (a.SchoolofAutomation,b.SchoolofComputer Science,GuangdongUniversityofTechnology,Guangzhou51o6,China)
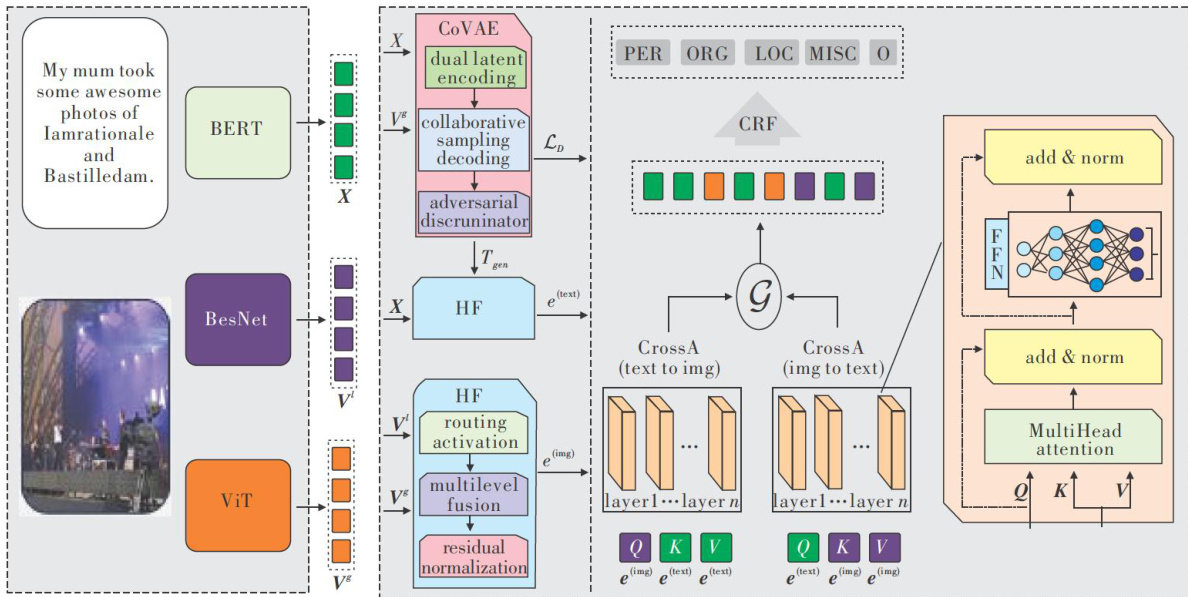
Abstract:MNERaimsto improve theaccuracyof named entityrecognitionbycombiningtextand image information.However,existingmethodsuderutilizethesemanticfeaturesofbothtextandimagesduetoirrgulartextexpressonsandtefocus of imagefeatureextractiononlocalinformationToaddressthisissue,thispaperproposedavisual-textcoperationandhierar chicalfusion(VTCHF)modelfornamedentityrecognition.Themodelutilized globalvisualfeatures tocomplementvisualsemanticsandfullleveragedboth imageand textfeatures throughacooperativeauto-variational encoder.Thisencodergenerated featurescontainingvisualcontextualinformation,whichsuppementedtextualsemantics.Furthermore,itdesignedaerarhicalfusionmoduletopre-fusetheimageand textfeaturesalong withtheirsemanticfeatures,enhancingthegranularityof visual semantics and mitigating alignment biases in subsequent fusion proceses.Experimental resultsonseveralpublicdatasets demonstrate that the model significantly improves the accuracy,recall,and F1 score of named entity recognition,validating the superiorperformance of the algorithm.
Key words:multimodal named entityrecognition(MNER);semantic alignment bias;semantic enhancement; modal synergy; attentionmechanism
0 引言
随着人工智能的迅猛发展,智慧课堂作为教育信息化的产物[1],正逐步演变为跨领域知识共享与协作的重要平台。(剩余21690字)
