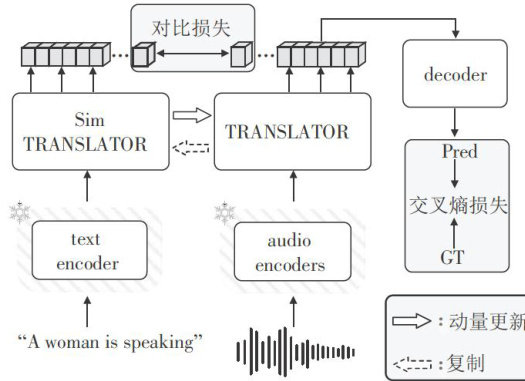
基于多模态表征学习的自动音频字幕方法

打开文本图片集
Tan Liwen’,Zhou Yi′ ,Liu Yin1,Cao Yin²+ (1.Scholofomucation&InfoationEnginering,Choging UniersityfPosts&elecomicains,hoging4oina; 2.Dept.of Intelligent Science,Xi'anJiaotong-Liverpool University,Suzhou Jiangsu 215ooo,China)
Abstract:Modalitydiscrepancies haveperpetuallyposedsignificant chalenges fortheapplicationofAACand acrossall multi-modalresearchdomains.Faciliatingmodelsincomprehendingtextinformationplaysapivotalroleinestablishinga seamless connection between thetwo modalities of textandaudio.Recent studies haveconcentratedonnarrowingthedisparity between thesetwo modalities viacontrastive learning.However,bridgingthegapbetweenthem merelybyemployingasimple contrastivelossfunctionishallenging.Inordertoreduceteinfluenceofmodal diffrencesand enhancetheutilizationf the modelforthetwomodalfeatures,thispaperproposed SimTLNet,anaudiocaptioning methodbasedonmulti-modalrepresentationlearning byintroducing anovelrepresentationmodule,TRANSLATOR,constructingatwin representation structure,and jointly optimizingthemodel weights throughcontrastive learning and momentum updates,which enabledthe model toconcurrentlylearnthecommonhigh-dimensional semantic informationbetwen theaudioandtextmodalities.Theproposed method achieves 0.251,0.782,0.480forMETEOR,CIDEr,and SPIDEr-FLon AudioCaps dataset and0.187,0.475,0.303 for Clotho V2dataset,respectively,whicharecomparablewith state-of-the-art methodsandefectivelybridgethediferencebetween the two modalities.
Key words:audio captioning;representation learning;contrastive learning;modality discrepancies;twin network
0 引言
自动音频字幕(AAC)是一项多模态生成任务,它联合音频和文本两种模态,生成音频的描述性字幕[1]。(剩余16830字)
