多维度交叉注意力融合的视听分割网络

打开文本图片集
doi:10.19734/j.issn.1001-3695.2024.08.0369
Audio-visual segmentation network with multi-dimensional cross-attention fusion
LiFanfan,Zhang Yuanyuan,Zhang Yonglong,Zhu Junwu† (School of Information Engineering,Yangzhou University,Yangzhou Jiangsu 2251Oo,China)
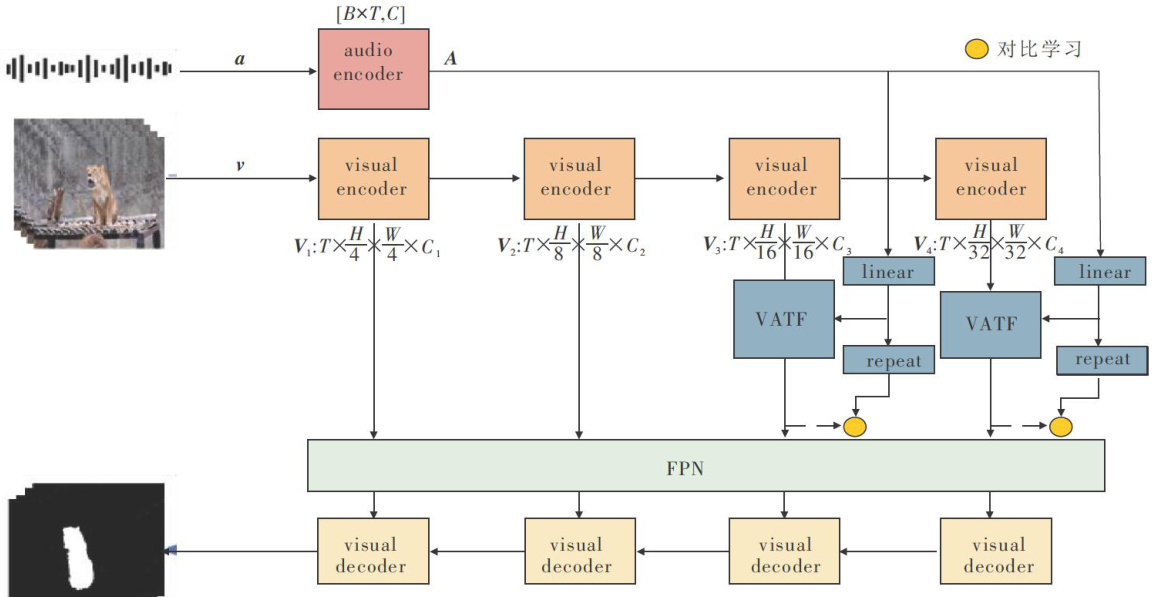
Abstract:Audio-visual segmentation (AVS)aimsto locateandaccuratelysegmentthesoundingobjects inimagesbasedon both visualandauditoryinformation.Whilemostexistingresearch focusesprimarilyonexploring methods foraudio-visualinformationfusio,thereisinsuicientin-depthexplorationoffine-grinedaudio-visualanalysis,particularlyinaligingcontinuousaudiofeatures withspatialpixel-level information.Therefore,thispaperproposedanaudio-visualsegmentationatention fusion(AVSAF)method basedoncontrastive learning.Firstly,themethodusedmulti-ead crossattentionmechanismand memorytokentoconstructaaudio-visualtokenfusionmodule toreducethelossofmulti-modalinformation.Secondlyitintro ducedcontrastivelearning tominimizethediscrepancybetweenaudioandvisualfeatures,enhancing theiralignment.Aduallayerdecoderwasthenemployedtoaccuratelypredictandsegment thetarget’sposition.Finalyitcarredoutalargeumber of experiments on the S4 and MS3 sub-datasets of the AVSBenge-Object dataset.The J -valueisincreasedby3.O4and4.71 percentage pointsrespectively,and the F valueis increased by 2.4 and3.5percentage points respectively,which fully proves the effectiveness of the proposed method in audio-visual segmentation tasks.
Key words:audio-visual segmentation;multi-modal;contrastive learning;attention mechanism
0引言
人类的感知是多维的,包括视觉、听觉、触觉、味觉和嗅觉。(剩余13740字)
