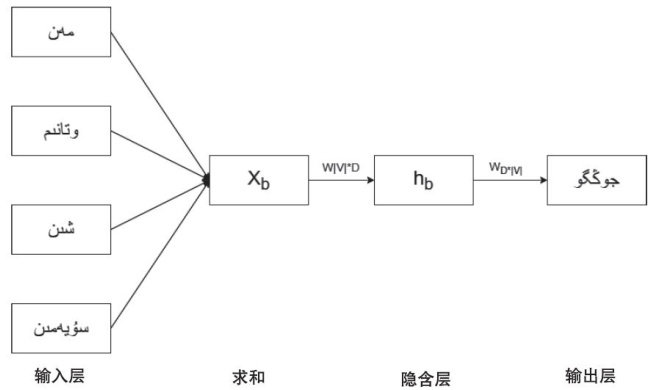
基于Word2vec的哈萨克文词向量化模型的实现

打开文本图片集
关键词:哈萨克文;Word2vec;词向量;相似度分析
doi:10.3969/J.ISSN.1672-7274.2025.05.050
中图分类号:TP31 文献标志码:B 文章编码:1672-7274(2025)05-0148-03
Abstract: The word vector embedding technology is a crucial step in the study of natural language processing, which is digitized through vectorization so that natural language can be recognized by computers and relevant processing calculations.The implementation of Kazakh language vectorization based on Word2vec is important to support the research in the feldof Kazakh language machine translation,text clasificationand recognition.In the article,the open-source iFLYTEK Kazakh corpus dataset is used as a corpus,and after cleaning,tokenization and other steps,vectorization is implemented to convert each Kazakh word intoan independentK-bit wordvector byusing Word2vc tol.Through thecomputation ofthese word vectors,the discoveryof thecontextual semantic patterns contained intheKazakhtext,the extractionofthe textual keywords,andthecomputation of the similar wordscan be achieved.
Keywords:Kazakh language;Word2vec;word vector;analysis
0 引言
随着“一带一路”倡议的不断深入。(剩余2828字)
