基于改进DDPG算法的复杂环境下AGV路径规划方法研究

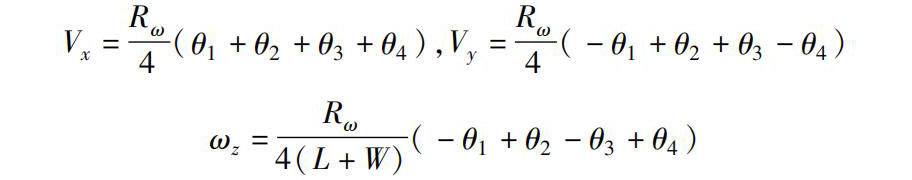
打开文本图片集
摘 要:为了提高AGV(automatic guided vehicle)在复杂未知环境下的搜索能力,提出了一种改进的深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法。该算法通过构建经验回放矩阵和双层网络结构提高算法的收敛速度,并将波尔兹曼引入到ε-greedy搜索策略中,解决了AGV在选择最优动作时的局部最优问题;针对深度神经网络训练速度缓慢的问题,将优先级采样应用于深度确定性策略梯度算法中;为解决普通优先级采样复杂度过高的问题,提出了利用小批量优先采样方法训练网络。(剩余18830字)
