基于改进遗传算法的计算机数学模型构建研究

打开文本图片集
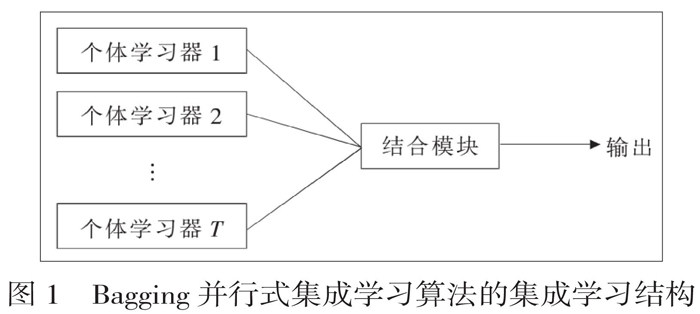
【摘要】 面向网络计算机中海量的数据信息,采取传统匹配搜索遗传算法进行匹配点、非匹配点的遍历,通常遍历到无效度更高的非匹配点较多,很难在短时间内找到与样本相近的最佳匹配点。基于此,针对基本遗传算法的无效遍历、数据冗余弊端,结合最小二乘法、Bagging集成聚类算法对原有遗传算法作出改进,建立起相似度匹配的计算机数学模型,确定高精度因子匹配的参数估算范围和辨识度,改进遗传算法关联矩阵编码、解码、交叉等集成学习与迭代环节,以扩展样本匹配的搜索空间与深度。(剩余5379字)
