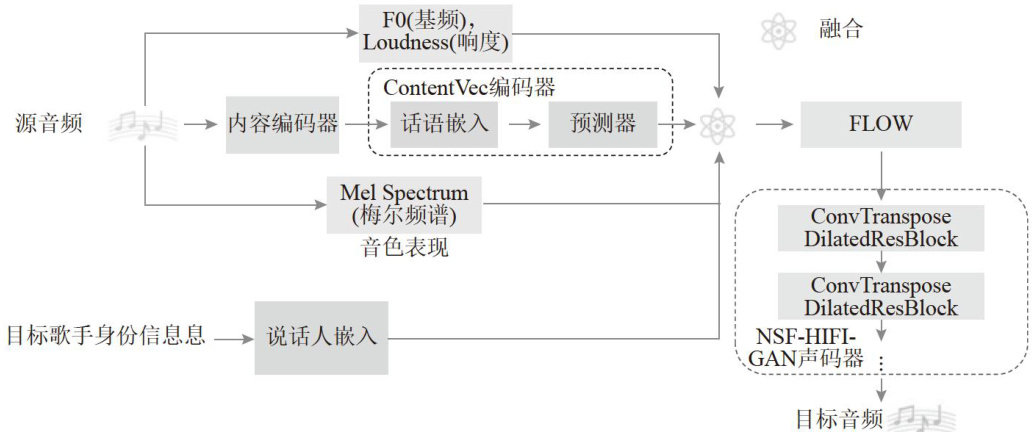
基于VITS的高性能歌声转换模型

打开文本图片集
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2025)12-0129-06
High-performance Singing Voice Conversion Model Based on VITS
ZHOUKeru,JIN Wei (SchoolofMedicalTechnologyandInformationEngineering,ZhejiangChineseMedicalUniversity,Hangzhou31oo3,China)
Abstract: Singing voice conversion is the processof transforming the voice of the source singer into that of the target singer whileretaining thoriginalcontentand melody.With the developmentof technology,various networkarchitectures and models have beenputforwardoneafteranother,and thealgorithms forsingingvoiceconversionhavealsobecomediversified. However,problemssuchaspoorqualityofteconvertedaudio,highdistortionrates,andlackofvocalrangeareboudtocur. This paperproposes UVC(Ultra Singing Voice Conversion)model with multi-decoupled feature constraints basedon highfidelityfow.This modelisbuiltonthebasisof theVITmodel.BycombiningtheContentVecencoderandtheNSF-HFI-GAN vocoder,itimproves theinputandoutputof the model,greatlyenhancingthequalityandfuencyoftheconvertedaudioand possessing strong robustness.
Keywords: singing voice conversion; VITS; ContentVec encoder; NSF-HIFI-GAN vocoder
0 引言
音乐一直是人类生活中不可或缺的一部分,歌声转换是指将源歌曲的声音转换成另一位歌唱者的声音的技术,旨在将源说话者声音的各个方面进行转换,如基频、频谱包络和韵律特征,使其与目标说话者的特征相匹配。(剩余10098字)
