支持向量机的大样本迭代训练算法

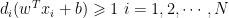
打开文本图片集
中图分类号:TP301.6 文献标识码:A 文章编号:2096-4706(2025)12-0085-07
Large Sample Iterative Training Algorithm for Support Vector Machine
CHEN Jimao
(Sanya Instituteof Technology, Sanya 572022, China)
Abstract: Aiming at the large sample training problem for Support Vector Machine (SVM),a new iterative training algorithmis proposed.Tobuildan initial training sample set,theK-meansclustering algorith is used tocompressthe training sample set,with each cluster centroid serving as the initial training sample set,reducing redundant information between samples toenhance trainingspeed.Toensure thetraining acuracy,theresultingcentroidistakenasthe initialsampleset, andthe boundarysamplesand misclasifiedsamples areaddedtothe initial sample setwithclassification.Anditis usedas trainingsamplesforiterativetraining until the numberof misclasifiedsamples is stable.Here,the K-means clustering SVM iterative training algorithmcanreduce thecomputational complexity while maintaining the training accuracyand improve the classification and training speed by optimization.
Keywords: Support Vector Machine; K-means clustering algorithm; iterative algorithm; Machine Learning
0 引言
支持向量机是最基本的模式识别与机器学习方法,应用相当广泛,其基本原理是用线性分类器将两类不同的信号特征数据显著分离。(剩余8144字)
