基于BERT-CRF的中文分词模型设计

打开文本图片集
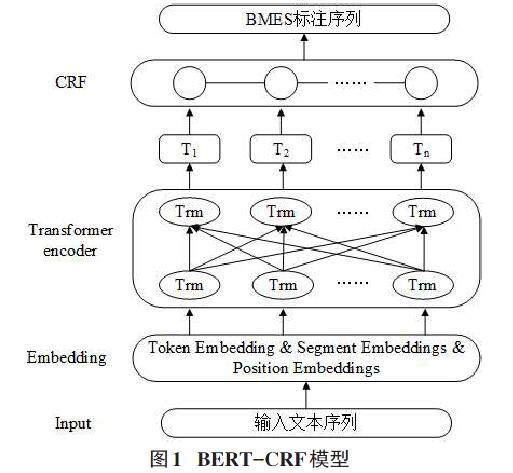
摘要:分词作为中文自然语言处理中的基础和关键任务,其分词效果的好坏会直接影响后续各项自然语言处理任务的结果。本文基于BERT-CRF的分词模型利用通用领域数据集与医学领域数据集对模型进行训练,分别取得F1值0.898和0.738的实验结果。
关键词:BERT;CRF;中文分词;自然语言处理
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)35-0004-03
自然语言处理(Natural Language Processing, NLP)是研究计算机理解和自然语言生成的信息处理[1]。(剩余4220字)
