基于多模态特征融合的场景文本识别

打开文本图片集
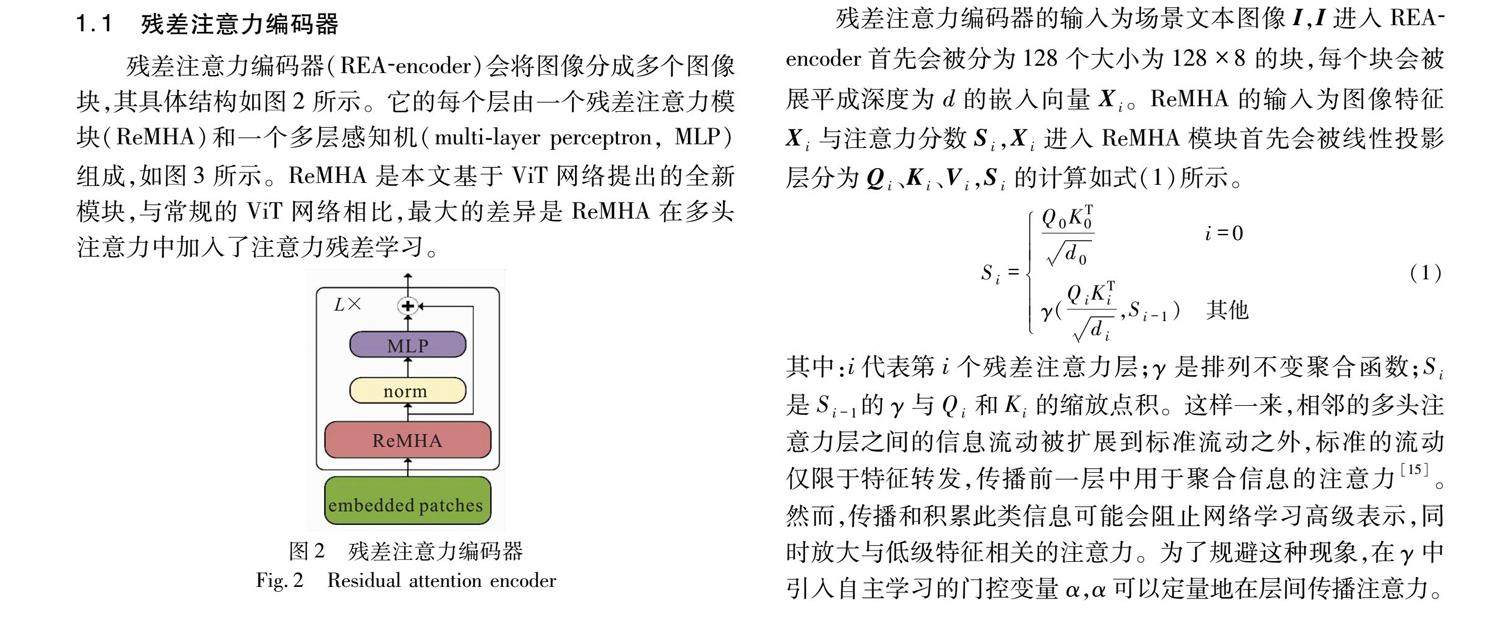
摘 要:为了解决自然场景文本图像因为遮挡、扭曲等原因难以识别的问题,提出基于多模态特征融合的场景文本识别网络(multimodal scene text recognition,MMSTR)。首先,MMSTR使用共享权重内部自回归的排列语言模型实现多种解码策略;其次,MMSTR在图像编码阶段提出残差注意力编码器(residual attention encoder,REA-encoder)提高了对浅层特征捕获能力,使得浅层特征能够传到更深的网络层,有效缓解了vision Transformer提取图像浅层特征不充分引起的特征坍塌问题;最后,针对解码过程中存在语义特征与视觉特征融合不充分的问题,MMSTR构建了决策融合模块(decision fusion module,DFM),利用级联多头注意力机制提高语义与视觉的融合程度。(剩余18683字)
