基于双通道时空融合注意力网络的多特征语音情绪识别模型

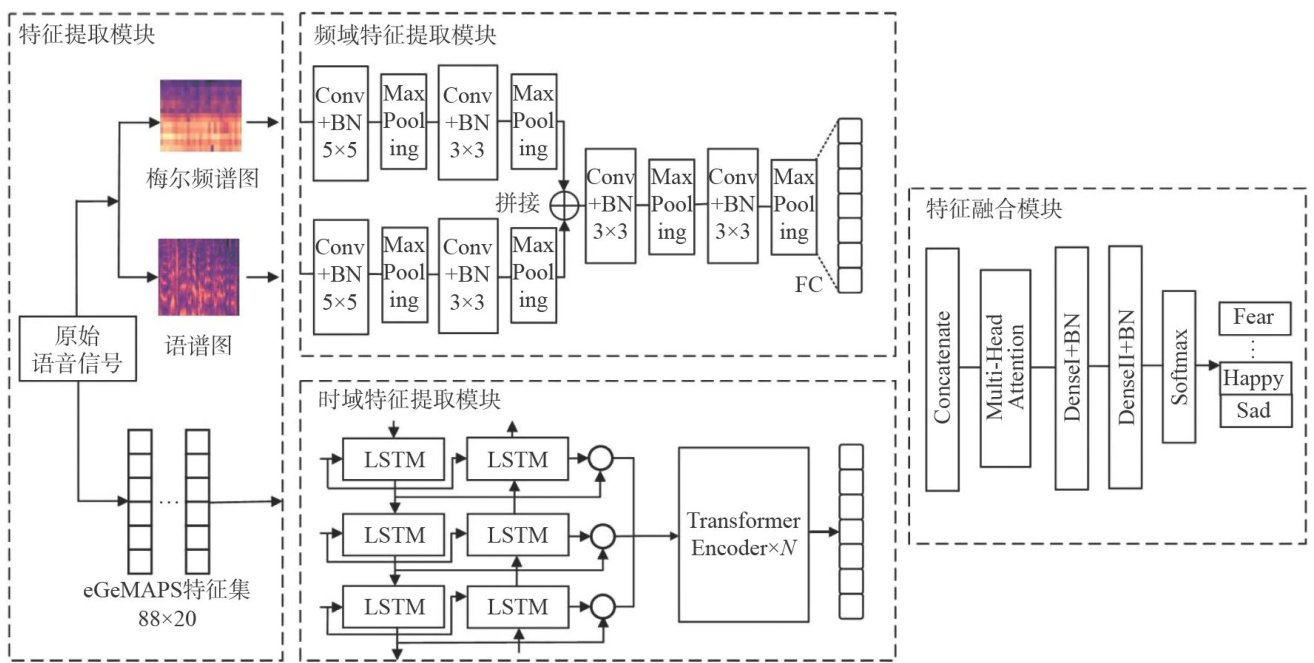
打开文本图片集
中图分类号:TB9;TP183 文献标志码:A 文章编号:1674-5124(2025)07-0001-08
Abstract: Aiming at the problem that Transformer has insuficient ability to extract temporal features and local information in speech emotion recognition, this article proposes anew deep learning architecture that integrates BiLSTM, Transformer and 2D-CNN. This model processes diffrent types of acoustic features respectively through two independent channels:the BiLSTM-Transformer channel is mainly used to capture temporal dependence and global context information, while the 2D-CNN channel focuses on extracting spatial features in Spectrograms and Mel-spectrogram. Meanwhile,this paper designs a multi-feature fusion strategy to effectively fuse the Spectrogram, Mel-spectrogram and eGeMAPS feature set, thereby enhancing the emotion recognition ability of the model. Experiments were conducted on the two datasets of CASIA and EMO-DB, achieving accuracy rates of 93.41% and 92.46% respectively. These results are significantly superior to the existing methods based on a single acoustic feature, indicating that the proposed multi-feature fusion strategy can effectively improve the emotion recognition performance of the model. Keywords: speech emotion recognition; BiLSTM; multi-feature fusion; Transformer
0 引言
语音不仅是人类交流的基本载体,也是情绪表达的重要方式[1]。(剩余12602字)
