基于双层数据增强的监督对比学习文本分类模型

打开文本图片集
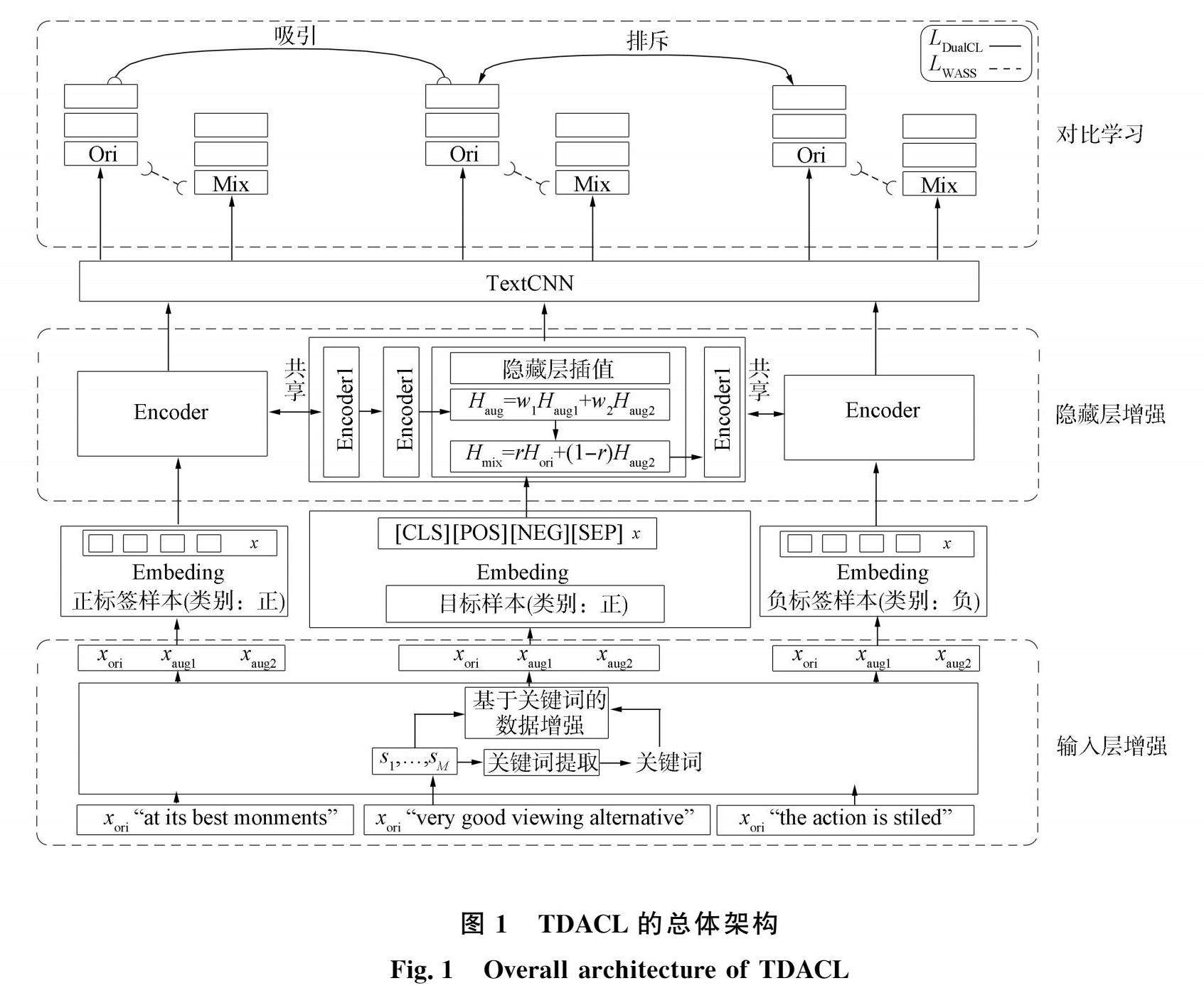
摘要:针对DoubleMix算法在数据增强时的非选择性扩充及训练方式的不足,提出一种基于双层数据增强的监督对比学习文本分类模型,有效提高了在训练数据稀缺时文本分类的准确率。首先,对原始数据在输入层进行基于关键词的数据增强,不考虑句子结构的同时对数据进行有选择增强;其次,在BERT隐藏层对原始数据与增强后的数据进行插值,然后送入TextCNN进一步提取特征;最后,使用Wasserstein距离和双重对比损失对模型进行训练,进而提高文本分类的准确率,对比实验结果表明,该方法在数据集SST-2,CR,TREC和PC上分类准确率分别达93.41%,93.55%,97.61%和95.27%,优于经典算法.
关键词:数据增强;文本分类;对比学习;监督学习
中图分类号:TP39文献标志码:A文章编号:1671-5489(2024)05-1179-09
Supervised Contrastive Learning Text Classification ModelBased on Double-Layer Data Augmentation
WU Liang,ZHANGFangfang,CHENGChao,SONGShinan
(College of Com puter Science and Engineering,Changchun University of Technology,Changchun 130012,China)
Abstract:Aiming at the non-selective expansion and training deficiencies of the DoubleMix algorithm during data augmentation,we proposed a supervised contrastive learning text classification model based on double-layer data augmentation,which effectively improved the accuracy of text classification when training data was scarce.Firstly,keyword-based data augmentation was applied to the original data at the input layer,while selectively enhancing the data without considering sentence structure.Secondly,we interpolated the original and augmented data in the BERT hidden layers,and then send them to the TextCNN for further feature extraction.Finally,the model was trained by using Wasserstein distance and double contrastive loss to enhance text classification accuracy.The comparative experimental results on SST-2,CR,TREC,and PC datasets show that the classification accuracy of the proposed method is 93.41%,93.55%,97.61%,and 95.27%respectively,which is superior to classical algorithms.
Keywords:dataaugmentation;textclassification;comparativelearning;supervised learning
文本分类是自然语言处理(NLP)的基本任务之一,在新闻过滤、论文分类、情感分析等方面应用广泛2,深度学习模型在文本分类中已取得了巨大成功,其通常建立在大量高质量的训练数据上,而这些数据在实际应用中并不容易获得,因此,为提高文本分类模型的泛化能力,当训练数据有限时,数据增强技术得到广泛关注[3,文本分类要获得较好的分类精度,好的特征表示和分类器的训练也至关重要[4].
在自然语言处理领域中,存在标记级别增强(token-level augment)、句子级别增强(sentence-level augment)、隐藏层增强(hidden-level augment)等类型[5].EDA6](easy data augmentation)是最常见的标记级别数据增强,通过对句子中的单词进行随机替换、删除、插入等操作实现数据增强.句子级别的增强通过修改句子的语法或结构实现,最常见的是反向翻译技术,隐藏层数据增强的方法是基于对数据插值(interpolation)实现的,Mixup是最早出现的一种基于插值的增强方式,TMix(interpolation in textual hidden space)是在其基础上发展的线性插值数据增强方式.Ssmix(saliency-based span mixup)是一种输入级的混合插值方式.上述几种插值方式都伴随伪标签(softlabel)生成,会限制数据增强的有效性.DoubleMix5增强方法的提出避免了伪标签生成,首先利用EDA与回译技术从原始数据中生成几个扰动样本,然后在隐藏空间中混合扰动样本与原始样本,最后采用JSD(Jensen-Shannon divergence)散度为正则项与交叉熵损失一起训练,但DoubleMix生成扰动样本的方式有的对句子结构要求较高,有的对文本进行非选择性的补充。(剩余11705字)
