面向密集人群场景的多径聚合姿态估计网络研究

打开文本图片集
关键词:多人人体姿态估计;YOLOv11;关键点检测;多尺度融合;小目标检测;深度学习中图分类号:TN911-34;TP391.41 文献标识码:A 文章编号:1004-373X(2026)09-0091-07
Multi-path aggregation pose estimation network for dense crowd scenarios
MiTaihang,Guo Chenxia,Yang Ruifeng (School of Instrumentand Electronics,North UniversityofChina,Taiyuan O3oo51,China)
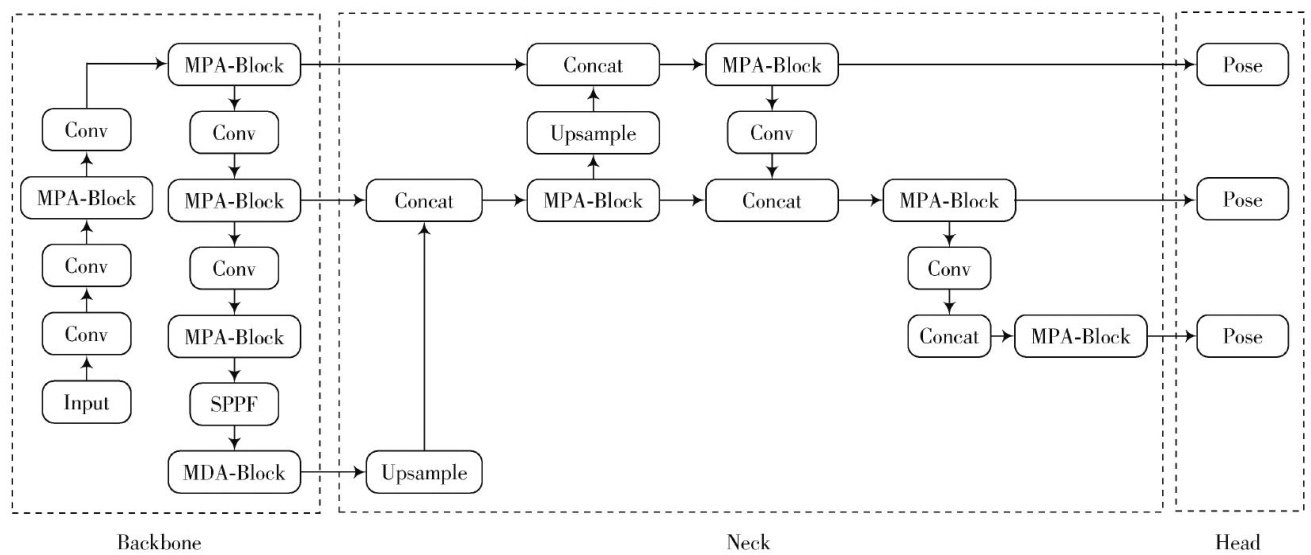
Abstract:In view ofthechalengesof diffcult feature extractionandlowrecognitionaccuracyofsmallobjectsinhuman poseestimation indensecrowdscenarios,thispaperdesignsamulti-pathaggegate block(MPA-Block).Itusesmulti-branch convolutiontosynergisticallyenhancethefeatureextractionabilityindensecrowdbackground,whichimprovesthe representationdimensionofmulti-levelfeaturesandavoidstheinsuficient featureextractionabilityofC3k2intheoriginal framework.Amulti-scaledilatedaentionblock(MDA-Block)isdesigned,whichmodifiesthespatialatention(C2PA)module viaamulti-scaledilatedatention(MDA)mechanism.Thismodification increases thenumberofselectable dilationrates,nabling themodeltodaptivelyfocusonfne-grainedlocalfeatures.Specificalytwodilationratesarededicatedtosmallobects,hreby improvingtherecognitionaccuracyofsmallobjectsindensescenarios.TheYOLOseriesalgorithmsareadoptedasthebasic framework,andaftercomprehensiveexperimentalcomparisons,YOLOv1withoptimalperformanceisselectedasthebncark model.Accordingly,amulti-scaleaggregationposenetwork (MSA-PoseNet)tailoredforcomplexscenariosisdeveloped. Experimental resultson the dataset CrowdPose demonstrate thatthe proposed methodachieves77.7%and47.7% in mAP @0.5 2 andmAP@0.5:0.95,respectively.Incomparisonwiththeoriginalmodel YOLOv11,theproposedmethodachievesan improvement of 2% and 2.3% in mAP@0.5 and mAP@0.5:0.95,which validates the effectiveness of the proposed method in the task ofcomplex crowd pose estimation.
Keywords:multi-person human pose estimation; YOLOv11; key point detection; multi-scale fusion;smallobject detection; deep learning
0 引言
视觉技术也不断发展,其理论研究和应用的方向也变得越来越广泛。(剩余11044字)