Scrapy框架辅助下的Python爬虫系统研究

打开文本图片集
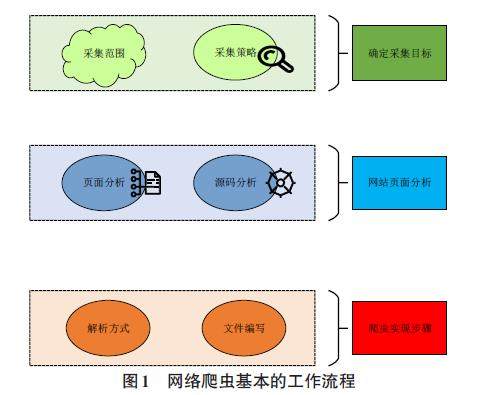
摘要:为了解决传统网络爬虫在大型网站上提取信息效率不高的问题,研究引入了Scrapy框架作为Python网络爬虫的提取方法。以某图书网站为案例,文章深入分析了该网站的页面结构,编写了高效的爬虫文件源码,用于提取目标网站的关键信息,包括图书名称、价格、定价、作者和销量排名等。研究结果表明,通过对主流网站的信息提取实验,在实际应用中展示了该方法取得了良好的效果,可以成功提出需要的信息,并根据提取出的图书价格和销量排名信息可以分析出价格与销量之间的关系,实现了对大型网站的信息提取任务。(剩余6720字)