基于特征识别和随机森林的网络数据流冗余去除算法
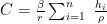
打开文本图片集
中图分类号:TP181 文献标志码:A
Abstract:Existing redundancy removal algorithms for network data often overlook data stream classification and strongly correlated redundant features,which impairs their effectiveness and reduces storage eficiency.This paper proposes a redundancy removal algorithm based on feature recognition and random forest techniques to address this issue.Initially,the stream atributesand timestamps were derived from the five-tuple of network data streams,and sample data weight values were calculated to assess marginality.Packet weights were assigned based on edge distribution characteristics to complete data stream classification.An active sampling method was employed to extractand identifyredundant informationfeatures.Finall,arandom forest algorithm wasutilized to construct a redundancy removal model. Through enhancements in feature selection and mixed sampling,the model effciently executed redundancy removal by encoding and replacing redundant data. Experimental results indicated that the proposed method could limit network bandwidth usage to less than six bps,significantly improving data storage efficiency.
Key words:feature recognition;improved random forest;network data stream classification; redundancy removal
当前网络数据流因其海量、高速、多变的特点,已成为大数据分析领域的重要研究对象。(剩余5567字)
