多尺度视觉增强语音驱动人脸生成

打开文本图片集
关键词:语音驱动;人脸生成;视觉增强;视觉质量
中图分类号:TP391文献标志码:A
DOI:10.7652/xjtuxb202506017 文章编号:0253-987X(2025)06-0167-10
Audio-Driven Talking Face Generation with Multi-Scale Visual Enhancement
YANG Xiangyan¹,LIANGHuihui²,CHEN Xi,LIFan²
(1. School of Computer Science and Technology,Xinjiang University,Urumqi 83o046,China; .Faculty of Electronic and Information Engineering,Xi'an Jiaotong University,Xi'an 71oo49,China)
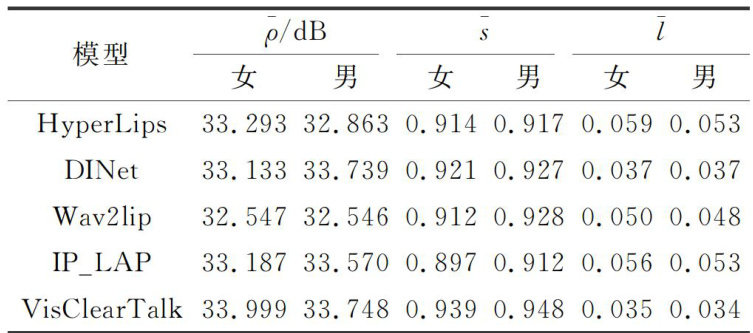
Abstract: To address the limitations of existing audio-driven talking face generation methods in terms of video clarity and realism,an end-to-end talking face generation method called VisClearTalk which incorporates multi-scale visual enhancement is proposed in this paper,and a face decoder with a visual enhancement module is proposed. First, the face encoder processed a random reference frame and a prior frame with the lower half of the face occluded to extract facial features. Simultaneously, the audio encoder extracted features from the audio to guide facial content generation. Subsequently, the face decoder integrated these features and performed an initial reconstruction of facial images through convolutional modules.Finall,the visual enhancement module employed multi-scale convolution and residual fusion to further enhance the details and edge information of the lower face region,improving the visual quality of the generated talking face videos. The VisClearTalk model was experimentally validated using public lip-reading datasets,with both quantitative and qualitative results demonstrating that the introduction of the visual enhancement module effectively improves the fineness and realism of facial visual content, enabling the generation of clear and natural talking face videos. In terms of performance metrics, the peak signal-to-noise ratio reached 34.349 dB, structural similarity reached O.933,and learnable perceptual image patch similarity was reduced to O. 040. The VisClearTalk model offers a viable solution for current talking face videos generation needs.
Keywords: audio-driven; talking face generation; visual enhancement; visual quality
语音驱动人脸生成是视听领域的重要研究课题之一[],其能够将视觉和听觉信息有机整合,增强人类对信息的理解和感知。(剩余14292字)
