基于 ConvTCN⁃FLASH⁃Transducer 的端到端语音识别

打开文本图片集
关键词: 语音识别; 时序卷积神经网络; FLASH 模型; RNN⁃Transducer; 特征提取; 挤压和激励机制中图分类号:TN912.34⁃34 文献标识码: A 文章编号:1004⁃373X(2025)12⁃0047⁃07
Abstract:A ConvTCN ⁃ FLASH ⁃ Transducer model based on the RNN ⁃ Transducer architecture is proposed to address the issues of insufficient extraction of local information from FBank audio by speech recognition encoders, insufficient exploration of temporal connections between frames, and high complexity of attention mechanisms. In this model, the combination of convolutional neural network module and fast linear attention with a single head (FLASH) attention module is adopted. The multi⁃ scale convolution is used to extract local information from audio features. The temporal convolutional neural (TCN) is used to extract temporal features between frames, strengthening the connection of local audio information. A squeeze and excitation mechanism is used to enhance the correlation between different channels, so as to increase the importance of key channels. Training and experiments were conducted on the Chinese open ⁃ source Mandarin dataset THCHS30. The results show that the final word error rate of the ConvTCN⁃FLASH⁃Transducer model is reduced to 4.2% , and the recognition effect is better.
Keywords: speech recognition; temporal convolutional neural; FLASH module; RNN ⁃ Transducer; feature extraction; squeeze and excitation mechanism
0 引 言
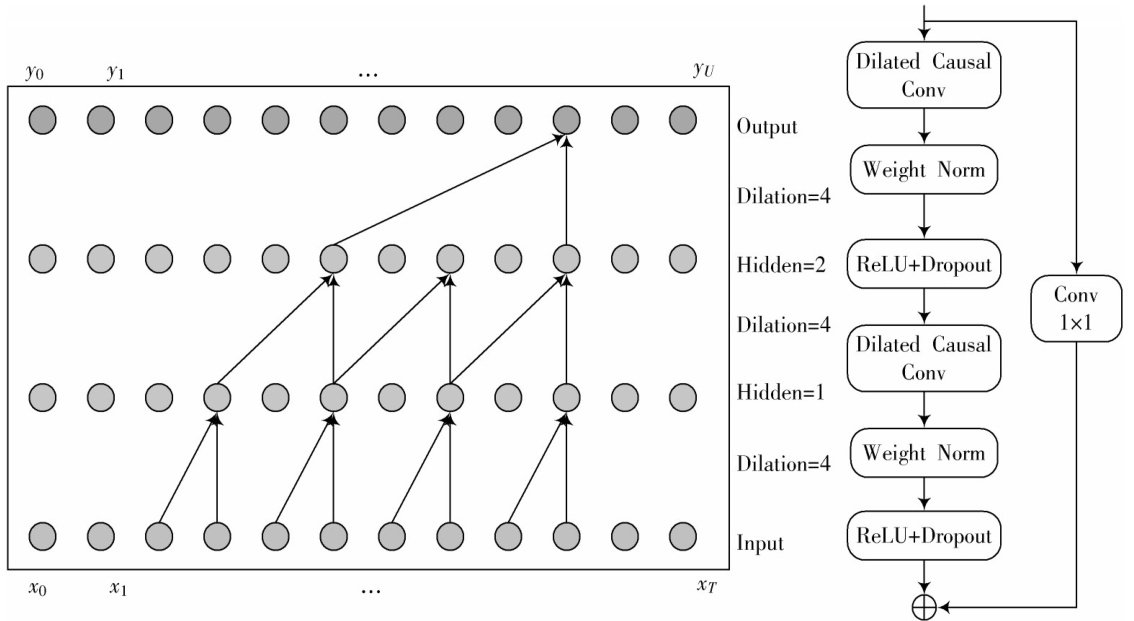
三部分都需要单独设计、训练,存在步骤繁琐、开发及维护成本高等问题。(剩余12805字)
