一种Q学习制作海克斯棋开局库方法

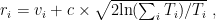
打开文本图片集
引文格式:[J].南通大学学报(自然科学版),2025,24(2):22-28.
中图分类号:TP312 文献标志码:A 文章编号:1673-2340(2025)02-0022-07
A Q-learning method for creating a Hex opening library
XUZhifan1,LIYuan1*,WANGJingwen',LIZhuoxuan²,CAOYiding³ (l.School of Science, Shenyang Universityof Technology,Shenyangllo87o,China; 2.SchoolofMathematics, SoutheastUniversity,Nanjing2lll89,China; 3.BaiyangEra (Beijing) Technology Co.,Ltd.,BeijinglOoo89,China)
Abstract: Hex is a perfect-information board game,and its opening library-an essential component of the game system—has traditionally been generated based on human expertise and Monte Carlo tree search (MCTS)algorithms. However,this approach is computationally expensive and may not consistently ensure acuracy.This study proposes a self-playmethod based on Q-learning for the eficientconstruction of Hexopening libraries.Theproposed method employs multi-threaded simulations and an improved upperconfidence bound applied to trees (UCT) algorithm to identify promising opening moves.An enhanced ε -greedy strategyis incorporated to improve the convergence rate of the Q-learning algorithm.To further improve performance,Q-values are integrated into the upper confidence bound (UCB) formula as prior knowledge,which is intended to enhance decision-making accuracy during gameplay.Experimentalresultsindicate that after 3Ooo training iterations,theQ-values acrossthe board converge,suggesting the method's potentialfor stable policy learning.Incomparativeevaluations,the generated opening library achieveda 62.9% average win rate against the improved UCT algorithm.When Q-values were used as prior input to the UCB formula,the averagewin rate increased to 75.9% . The method was also applied in the Chinese Computer Game Competition,where theimplementationreceivedafirst-placeaward,supporting thepracticalapplicabilityof theapproach. Key words: computer game; Hex;reinforcement learning;Q-learning; opening library
计算机博弈作为各个领域博弈理论的起源与基础,可用于研究人类思维的模式和规律,模仿人类下棋,提高人类智能水平[1-3]。(剩余10800字)