AIIMix用于标签噪声学习的图像分类方法

打开文本图片集
中图分类号:TP183文献标志码:A
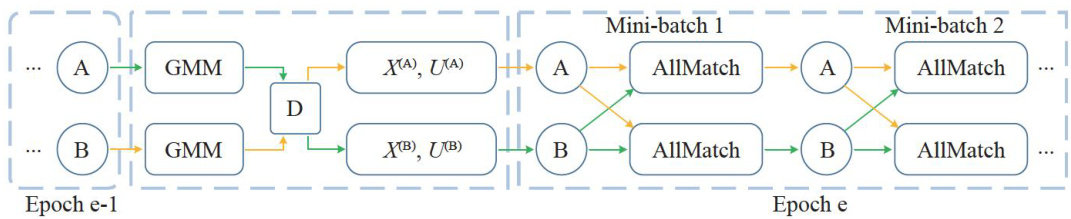
Abstract: Datasets collected and annotated manually are inevitably contaminated with label noise, which negatively affects the generalization ability of image classification models. Therefore, designing robust classification algorithms for datasets with label noise has become a hot research topic.The main issue with existing methods is that self-supervised learning pre-training is timeconsuming and still includes a large number of noisy samples after sample selection. This paper introduces the AllMix model, which reduces the time required for pre-training. Based on the DivideMix model, the AllMatch training strategy replaces the original MixMatch training strategy. The AllMatch training strategy uses focal loss and generalized cross-entropy loss to optimize the loss calculation for labeled samples. Additionally, it introduces a high-confidence sample semisupervised learning module and a contrastive learning module to fully learn from unlabeled samples.Experimental results show that on the CIFAR1O dataset, the existing pre-trained label noise classification algorithms are 0.7%,0.7% ,and 5.0% higher in performance than those without pre-training for 50% , 80% ,and 90% symmetric noise ratios, respectively. On the CIFAR100 dataset with 80% and 90% symmetric noise ratios, the model performance is 2.8% and 10.1% (204号 higher, respectively.
Keywords: label noise learning; image classification; semi-supervised learning; contrastive learning
引言
卷积神经网络(convolutionalneuralnetwork,CNN)等深度学习技术已广泛应用于图像分类领域[1-3]。(剩余11564字)
