基于多尺度Transformer特征的道路场景语义分割网络

打开文本图片集
中图分类号:TP391.41;U491.1 文献标志码:A
本文引用格式:.基于多尺度Transformer特征的道路场景语义分割网络[J].华东交通大学学报,2025,42(2):110-118.
Road Scene Semantic Segmentation Network Based on Multi-Scale TransformerFeatures
PengYang,Wu Wenhuan, ZhangHaokun
(SchoolofIntelligentandConnected Vehicle,Hubei UniversityofAutomotiveTechnology,Shiyan442o02,China)
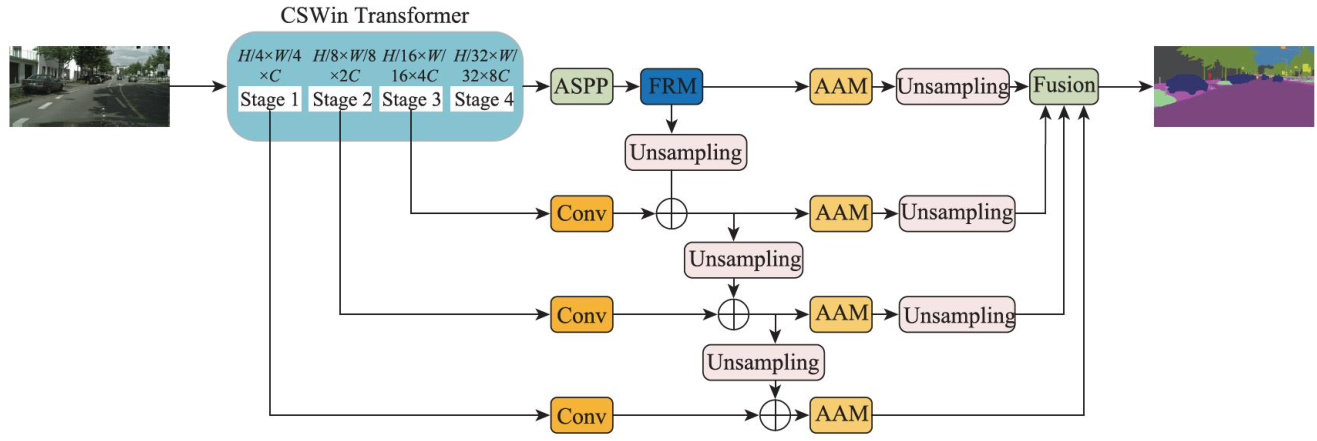
Abstract: Image contents in road scenes are usually complex, with significant differences in scale and shape between different objects,and lighting and shadows can make the scenes difficult to recognize.However,existing semantic segmentation methods often fail to effectively extract and fully integrate multi-scale semantic features, resulting in poor generalization ability and robustnes.To address these issues,this study proposes a semantic segmentation network model that fuses multi-scale Transformer features.Firstly,the CSWin Transformer was employed to extract semantic features at various scales,accompanied by the introductionofa feature refinement module (FRM) to enhance the semantic discrimination capability of deep,fine-grained features. Secondly,an attention aggregation module (AAM) was adopted to separately aggregate features across scales.Finally,by integrating these enhanced multi-scale features,the semantic expression ability of the features was further enhanced, thereby improving segmentation performance. Experimental results demonstrate that this network model achieves an accuracy of 82.3% on the Cityscapes dataset, outperforming SegNeXt and ConvNeXt by 2.2 percentage points and 1.2 percentage points, respectively. Moreover, it attains an accuracy of 47.4% on the highly challenging ADE20K dataset, surpassing SegNeXt and ConvNeXt by 3.2 percentage points and 2.8 percentage points,respectively.The proposed multi-scale Transformer feature fusion model not only achieves high semantic segmentation accuracy,accurately predicting pixel semantic categories ofroad scene images, but also has strong generalization performance and robustness.
Key words: semantic segmentation; Transformer features; feature fusion; spatial expectation maximizes attention; channel attention
Citation format: PENG Y,WU WH, ZHANG HK.Road scene semantic segmentation network based on multi scale transformer features[J]. Journal ofEast China Jiaotong University,2025,42(2): 110-118.
语义分割的目标是识别出图像中每个像素所属的物体类别标签。(剩余12740字)
