语言资源视角下的大规模语言模型治理

打开文本图片集
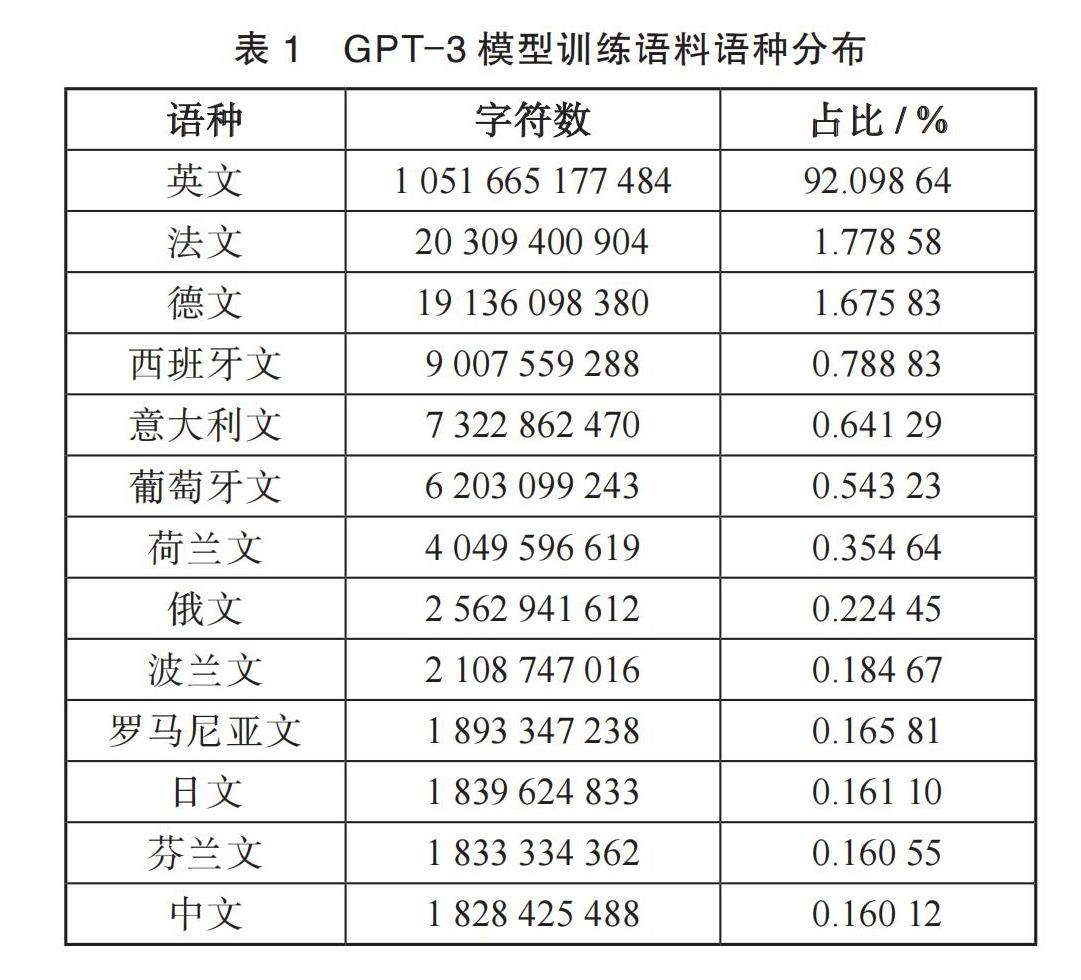
提 要 近半年来,柴语生(ChatGPT)等大规模生成式语言模型的应用,引发了全社会的关注和反思。对这种大模型,应以工具观加以正视,认可其技术发展带来的益处,同时尽量规避其风险。对它们的治理,应减少对技术本身的干预,将目标定位于大模型赖以研发的语言资源和投放之后的使用。对大模型研发中的语言资源治理,应着力打破中文数据孤岛:发展以联邦学习为代表的分布式模型构建技术,建立国家知识数据开放机制,尽快健全开放、高效的语言数据交换市场;提倡世界知识中文表达,助推中文大模型研发:尽快实现中文精华知识资源面向网络开放,完善中文概念、术语资源,做大、做全领域中文资源。(剩余14979字)
